
1.辞書引き

では、機械翻訳の核である「構文解析」を、実例を用い、図解を交えながら追跡していってみましょう。
まず、辞書引きで、文中の単語に、品詞情報が割り当てられます。ここでは説明を簡単にするため、それぞれの単語に1種類の品詞情報だけが割り当てられたものと仮定します。

上に、たとえば“book”は「名詞」と指定してありますが、実際には、この単語がどのような種類の名詞であるかという細かい指定がされています。たとえば、
(a)単数名詞であるかどうか。
(b)不定冠詞”a”で修飾可能であるかどうか。
(c)副詞的名詞として使用可能であるかどうか ( "book"は不可能、“morning”は可能)。
などという細かい構文的特徴の指定です。
現在のロゴヴィスタ翻訳ソフトの辞書では、すべての名詞項目について、(a. b. c)も含めて、40余りの構文的特徴の指定を行っています。また、動詞、形容詞などについても、その構文的特徴について、20余りの指定を行っています。
2.構文解析
第2のプロセスは構文解析です。構文解析は、(2)から得られる(3)という品詞系列に対して行われます。

この系列を使って文構造が得られるものかどうかの判定です。どのような文構造が英語に許されるかは、文法規則で指定されています。たとえば、次の規則が文法に含まれているとしましょう。

構文分析は、(4)のような規則を使って品詞系列(3)のグルーピングを行いながら、品詞系列全体が「文」として分析できるかどうかを判定するプロセスです。(3)の品詞系列を構文分析すると、この系列が図1に示すような構造を持った「文」であることが分かります。
図1の構文木で、頂点の「文」から「平叙節」と「終止符」という枝点に2つの枝が伸びている構造は、規則(4a)によります。同構文木の中で、「平叙節」という枝点から、「名詞句」と「動詞句」という枝点に2つの枝が伸びている構造は、規則(4b)によります。
構文解析の途中で、名詞句の文法数と動詞句の文法数が一致しているかのチェック、名詞が不定冠詞で
修飾され得るものであるかどうかのチェック、不定冠詞の文法数と名詞の文法数が一致しているかどうかのチェックなどが行われますが、図1の構造は、これらのテストを無事パスしています。
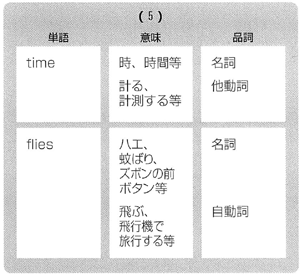
次に“Time flies.”という文の解析を見てみましょう。現在の辞書では、“time”に7品詞、“flies”に19品詞が登録されていますが、解説を簡単にするため、(5)にその一部だけを示します。
文法には、(6)に示す規則も含まれています。
命令節に用いられる「動詞句」は、もちろん不定形の動詞句(動詞が辞書に登録されている原形)でなければなりませんが、この条件も、「命令節=動詞句」という規則の中に指定されています。

(4)と(6)の規則を含んだ文法を使って“Time flies.”を構文解析すると、図2と図3に示す二つの構造木が得られます。
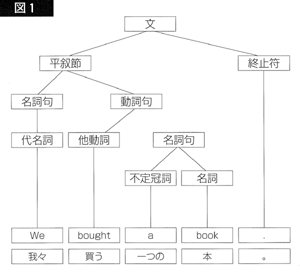
図2の構文木は、「時は飛ぶ」という平叙文に対応し、図3の構文木は、「ハエを計れ」という命令文に対応します。
上の説明で、与えられた単語、たとえば“time”が辞書引きの結果として名詞という品詞を割り当てられたら、その意味がいくら多岐にわたっても、構文解析の過程では、単一の品詞として取り扱われるかのように述べましたが、実は、辞書の中で、名詞として繰り返して登録されている単語が数多くあります。たとえば、“man”には「男の人・部下」などの意味の名詞登録に加えて、「人間」という意味の別個の名詞登録があります。なぜかというと、この二つの名詞は、異なった細分化構文法的特徴を持っているからです。たとえば前者は“a”で修飾され得ますし、“a”あるいは他の冠詞(たとえば“the,this,my”)なしで名詞句を作ることができません。他方、「人間」の意味の“man”は“Man
is mortal.”「人間は死を免れない。」のように、“a”あるいは他の冠詞なしで用いられることができます。このようなわけで、与えられた文に対して、構文解析に入力される品詞系列の数は「異なり品詞の系列」よりはるかに多くなるのが通常です。先に“Time
flies”の“time”には7品詞あると述べましたが、これは、名詞としての“time”を一品詞として数えたもので、実際には“time”は名詞として、9項目登録されています。なぜなら、たとえば“Time
is money”「時は金なり」の“time 時”、“It took along time”「それは長い時間を要した」の“time
時間”、“What time is it now? ”の“time 時”、“This is the third time
that it has happened”「これはそれが起きた3回目である」の“time”はそれぞれ異なった細分化構文法的特徴を持っているからです。従って、辞書引きの結果“time”に与えられる品詞の総数は、15ということになります。
“flies”に与えられる品詞の数は先に述べたように19ですから、この文の品詞系列の総数は15×19=285ということになります。
終止符を含めて3単語に過ぎない文の構文分析に285の品詞系列を処理しなければならないのですから、30単語、40単語、50単語の文(普通の文章には普通に現れる長さの文)に可能な品詞系列の数がいかに大きいか、想像がつくことと思います。細分化構文
法的特徴は、このように、構文解析が処理しなければならない品詞系列の数は増やしますが、厳しい構文法的制約を指定しているわけですから、構文解析で許される構文木の数は、大幅に削減します。
構文解析の終わりに、得られた構造木が入力文の意図した構造を正しく表わしているかいないかの蓋然性チェックがいろいろな角度から行われます。このチェックの第1は、解析に用いられた文法規則の蓋然性チェック、第2は、それぞれの単語に対して選択された品詞の蓋然性チェックです。文法の中の規則一つ一つに、その規則が表わす構造が入力文テキストに現れる蓋然性指数が附加されています。たとえば
“We bought a book”に対応する「名詞句+動詞句」パターンの平叙節の頻度数のほうが“Up jumped
the rabbit.”のような倒置平叙節よりはるかに頻度数が高いので、前者の規則(4a)には、倒置平叙節の規則よりはるかに高い蓋然性指数が附加されています。
また、辞書の中には、与えられた単語が与えられた品詞で用いられる蓋然性を表わす指数が附加されています。たとえば、“smell”という単語が名詞として用いられる頻度数は、それが単純自動詞や単純他動詞
として用いられる頻度数より高いので、辞書の中で、“smell 名詞”に、“smell 単純自動詞”や、“smell 単純他動詞”より高い蓋然性指数が附加されています。他方、“smells”という単語が名詞として用いられる頻度数は、それが単純自動詞や単純他動詞として用いられる頻度数より低いので,“smells
名詞”の蓋然性指数は、“smells 単純自動詞”や“smells 単純他動詞”よりも低くなっています。辞書の中の蓋然性指数の指定は、主に辞書コーダー(英語を母国語とする人たち)の直感的判断によるものですが、中には、単語の品詞別統計表を参考にしながら附加されたものもありますし、大きい英文データベースから作られた文脈付き索引を参照しながら附加されたものもあります。
さて、図2と図3に示された2つの構文木の総合的蓋然性が、このステージで計算されます。それぞれの構造木の中で用いられているすべての文法規則の蓋然性指数の積が、構文木の総合文法規則蓋然指数ですし、個々の単語の品詞に附加されている品詞の蓋然性指数の積が、その構文木の総合品詞蓋然性指数となります。この2つの総合蓋然性指数の和が、構文木の総合文法規則・
品詞蓋然性指数です。ロゴヴィスタの翻訳エンジンは、総合文法規則蓋然性指数と総合品詞蓋然性指数との間にどのような比重を置いたら、正しい構文木が一番高いランク付けをされる確率が高くなるかを調節できるようにデザインされています。
現在の文法では、平叙文規則(4a)に、命令文規則 (6a)よりも高い蓋然性指数が附加されています。また、辞書の中で、“time
名詞”に対して、“time 単純他動詞”よりも高い蓋然性指数が附加されています。このような蓋然性指数の総合によって、平叙文としての
“Time flies.”の構文木が、命令文としての“Time flies.”よりも高い蓋然性ランク付けを受けます。
文法規則の蓋然性指数、辞書項目での品詞選択の蓋然性指数に基づいた構文木ランク付けと平行して、構文木がバランスのよく取れた構造を表わしているかどうかのテストが行われます。英語は、文の途中に長い複雑な要素が現われ、その後に短い要素が現れることを嫌います。たとえば、

は、理論的には、「ジョンは、彼が昨日病気であったと言った。」という意味と、「ジョンは、彼が病気であったと昨日言った。」という2つの意味を持っていますが、前者の意味に解釈されるのが普通です。なぜかというと、後者の解釈では、“that he was sick”という長い節が、“said ... yesterday”という動詞句の 真ん中に現れているからです。
(7)を翻訳エンジンで解析すると、当然、下の2つの構文木が出てきます。

構文バランステストは、(8a)の構造については、バランスが取れているという評価をしてボーナスを与え、(8b)の構造については、バランスが取れていないという評価をして、罰金を加えます。すなわち、構文バランステストは、(8a)の構造は、入力文の極めて蓋然性が高い構文木であるけれども、(8b)の構造は、蓋然性が低い構文木である、という判断をするわけです。このようにして得られた構文バランスボーナス・罰金数値は、文法規則蓋然性指数や品詞蓋然性指数と比較できるような指数に変換されて、構文木ランク付けの基準の一つとして用いられます。
3.基本文型化

基本文型化プロセスで、たとえば、“How bright do you think John
is?”「あなたはジョンがどれぐらい頭が良いと思うか?」は、“You do think John is how
bright?”の構文木に変換されます。また、“How many foreign languages do you
think Mary can speak?”「あなたはメアリーがいくつの外国語を話すことができると思うか?」は、“You
do think Mary can speak how many foreign languages?”の構文木に変換されます。このような変換を加えると、形容詞、
動詞の主語は必ずその前にあり、動詞の目的語は、必ず動詞の後に現れることになり、次に述べる意味解析の適用が単純化できます。
ロゴヴィスタの機械翻訳プロセスの第3段階は、ランク付けの高い構文木の基本文型化です。この段階で、何が行われるかを“What
can you do?”を用いて 説明します。翻訳エンジンに、(4)と(6)に加えて、次の規則が含まれているとします。
(9b)の「欠疑問節」は、名詞句が一つ欠けている疑問節です。たとえば、“can you
do”という疑問節は、
“do”の目的語名詞句が欠けていますから、欠疑問節です。
(9c)の<t>は、疑問文で、主語・助動詞の倒置が行われる以前の段階で、助動詞が占めていたポジション、すなわち<助動詞痕跡>を表わします。この痕跡は、構文解析自体では無視されますが、解析が終わった後の構文木作成の段階で木の中に明記されて現れます。
同じく(9c)の「欠動詞句」というのは、名詞句が欠けている動詞句のことです。“What
can you do?”の“do”は、もともと“do what”という目的語を伴った動詞句だったものが、疑問名詞句の文頭移動によって、目的語を欠いた動詞句になっ
たわけです。
(9d)の<e>は、疑問名詞句の文頭移動以前のポジション、すなわち<名詞句痕跡>を表わすものです。この指定も、構文解析そのものでは無視されますが、構文木を作る段階で、挿入されます。
それでは、“What can you do?”の構文木を見てみましょう。
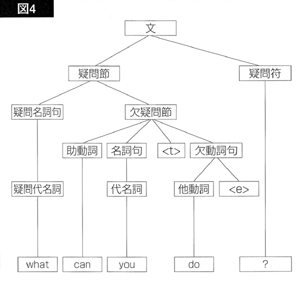
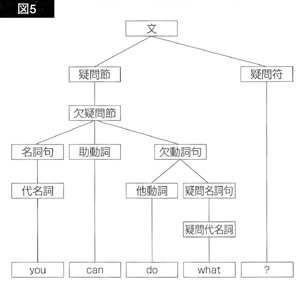
図4の構文木は、文の構文解析が終わり、構文木作りの段階で、助動詞痕跡<t>と名詞句痕跡<e>が挿入された後の構文木を表わします。この構文木は、基本文型化によって、図5の構文木に変換されます。すなわち、文頭の疑問名詞句は、その文頭移動以前のポジション<t>に戻され、助動詞は、主語・助動詞倒置以前のポジション<e>に戻されます。
実際には、「助動詞+欠動詞句」が「動詞句」を構成するという指定や、欠動詞句も動詞句であるという指定が文法規則の中に附加されていて、基本文型化された構文木は、図5の構文木よりも、もっと基本文型化されていますが、説明が煩雑になるので省略します。
4.意味解析

ロゴヴィスタの翻訳プロセスの第4段階は、意味解析です。この段階で基本文型化された構文木の一つ一つについて、それぞれの単語の意味付け
(たとえば、名詞と判定された“flies”は「ハエ」 か「蚊ばり」か「ズボンの前ボタン」か)が行われます。この意味付けの結果、一つの構文木から、複数個の構文・意味木(以後単に「意味木」と呼びます)が作り出されます。たとえば、現在の辞書の中で、単純自動詞“flies”には、次のような異なった意味があり、そのそれぞれについて、どういう種類の主語をとることができるかが指定されています。(実際には、“flies”の原形“fly”にこの指定がされています。)
(10a,b,c)などの意味指定に附加されているP(60)、P(30)、P(1)などというP値(確からしさの指数)は、
単純自動詞としての“flies”が「飛ぶ」という意味で用いられる蓋然性、「飛行機で旅行する」という意味で用いられる蓋然性、「(旗が)翻る」という意味で用いられる蓋然性を表わす指数です。これらの数値を「個別訳語蓋然性指数」と呼べば、与えられた意味木の総個別訳語蓋然性指数は、文の単語に選ばれた訳語に附加されている個別訳語蓋然性指数の積
(の対数)で表わすことができます。
(10b)の「飛行機で旅行する」という訳語に附加されている主語「人間」という指定は、“flies”が「飛行機で旅行する」という意味を取るのは主語が「人間」という意味素性を持っているときに限られる、という指定です。と言っても、“Time
flies”の「時は飛行機で旅行する」に対応する意味木は考慮から外してよいというわけではありません。この意味木は、「飛行機で旅行する」が要求する主語「人間」という条件を満たしていないので罰金を受けますが、一つの可能な意味木として保持され、他の意味木と比較されます。このようにしておかないと、比喩的表現の意味木が考慮から外されてしまうからです。
(10)の個別訳語指定に戻って、(10c)の主語「布・“flag”・“banner”」というのは、“flies”が「翻る」の意味で用いられるのは、主語が「布」という意味素性を持っているときにかぎられる、そして、主語が
“flag”か“banner”という単語である場合には、“flies” が「翻る」という意味で用いられている蓋然性が一層高くなる、という指定です。この場合も、主語「布」という指定は、絶対的なものではなく、与えられた意味木でその指定が守られていればボーナスが与えられ、守られていなければ罰金が与えられるという性格の指定です。
例文“Time flies.”の名調の“time”にも5つの異なった意味指定がされていますが、説明を簡単にするため
次の一つに絞ります。

図2の構造木から、計9×5=45の意味木のセットが作り出されるわけですが、図6と図7にその二つを示します。
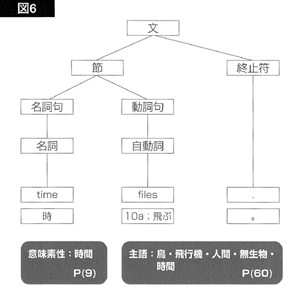
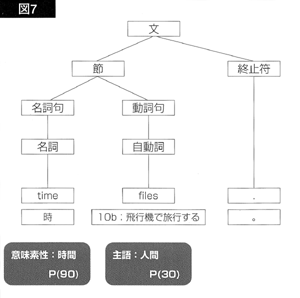
図6の意味木は、「飛ぶ」が要求する[鳥・飛行機・人間・無生物・時間]という主語の意味素性と、主語「時間」に附加されている「時間」という意味素性の間に「時間」という接点があります。従って、この意味木には、ボーナス点が与えられます。ボーナスは、「意味素性木」のどの点で接点が得られたかによって、その額が違ってきます。ここで「意味素性木」というのは、意味素性間の関係を表わす意味素性構造木のことです。たとえば、図8に示すような意味素性木があるとしましょう。
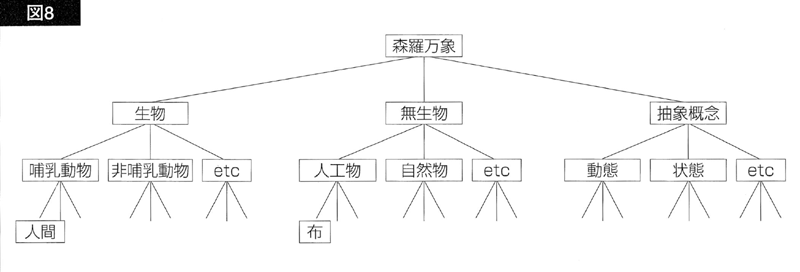
図8の意味素性木の中で、任意の意味素性は、その上の意味素性も兼ね備えています。たとえば、ある単
語の名詞的用法に「人間」という意味素性指定があれば、それは、「哺乳動物」でもあり、「生物」でもあることを示します。
動詞や形容詞がその主語に要求する意味素性と主語の名詞が持っている意味素性の接点が、「意味素性木」のどの点にあるかによってボーナスの額が違ってくる、というのは、その主語としてどのような意味の名詞をとることができるかという指定の緩さ、厳しさに由来します。たとえば、“live
自動詞 <生きる>”には主語「生物」という指定がなされていますが、「生物」という意味素性は「意味素性木」の頂点「森羅万象」の直ぐ下にある意味素性ですから、この指定は極めて緩い幅の広い指定です。動詞が主語に要求する意味素性と、主語の意味素性の接点が[生物]であっても、幅の広い指定で合致しているに過ぎませんから、特筆すべき合致ではありません。従ってこの場合のボーナスは、額が少ないようになっています。他方、たとえば、“The
flag files at half mast.”が入力文である場合、“flies 自動詞
10c: 翻る 主語「布」” と “flag 名詞 意味素性「布」”の接点は、意味素性 「布」であって、この意味素性は、「意味素性木」の
下位の要素です。意味素性木の下位の要素で主語の意味素性が指定されているということは、“flies 翻る”について非常に狭く厳しい主語条件が付いているということです。そのような条件はそう数多くの単語で満たされるわけではありませんから、実際その条件が満たされている場合は、特筆すべき合致、「特別ボーナス」に値するべき合致です。このように、意味素性接点に与えられるボーナスは、その接点が
「意味素性木」の中で占める位置に基づいて計算されます。更に、“flies”の主語意味素性指定に、「単語 “flag”か“banner”
(およびその複数形)が主語の場合には、ボーナスの額を更に増やせ」という指定があるので、“flies 翻る”を含んだ“The
flag flies at half mast.”の意味木は、多額なボーナスを受けることになります。このようにして得られる「旗は翻る」の意味木ボーナス値は、“flies
翻る”に附加されている極めて低いP値を補って余りあるものなので、この意味木がもっとも高いランク付けを受けることになります。
ロゴヴィスタ翻訳エンジンは、上記の意味解析ボーナス・罰金指数のほかに、意味素性に基づいた他のいくつかの評価指数を行っていますが、説明が煩雑になるので、ここでは割愛いたします。

ここで、ロゴヴィスタの英日翻訳エンジンの文法、辞書の規模を表わす数値をいくつか出しておきましょう。辞書、文法の中で現在用いられている品詞の総数は、900余り、そのうち、動詞品詞(例えば単純自動詞、単純他動詞、2重目的他動詞など)の数は110余り、形容詞品詞(単純形容詞、前置詞句をとる形容詞、節をとる形容詞など)の数は15。名詞一つ一つに付されている細分化構文法的特徴指定は、すでに述べたように、40余り、動詞、形容詞一つ一つに付されている細分化構文法的特徴指定は24。文法規則の総数は、12,400、辞書項目の総数は(専門辞書を除いて)
300,000、意味素性木の中で認められている意味素性の数は、330。これらは、10年近く続けて開発されてきた文法、辞書情報のスケールとその詳細さの一端を表わす数値です。

上に、与えられた入力文の構文解析木の蓋然性指数に始まって、意味木にいたるまでのいくつかの評価指数を説明してきました。これをまとめて列記すると(12)のようになります。
これらの評価基準のそれぞれを構文意味解析のエキスパートと考えます。それぞれのエキスパートは自分の専門に応じて、与えられた複数個の構文木、あるいは、意味木を、好ましい順に並べ、その好ましさ加減を表わす数値を提供します。これらの意見を、エキスパート・マネージャが総合して、構文・
意味木を正解の蓋然性に従って、格付けします。ロゴヴィスタは、経験的にどのエキスパートの意見に比重を重く置いたら、正しい構文意味解析がトップに出てくる蓋然性が一番高くなるかを調整できるようにできています。もちろんこの調整をする機能は、製品には含まれていませんが、製品に入っている調整値は、10年近くかかって、数多くの入力文のテスト翻訳に基づいて行ってきたファイン・チューニングの結果です。
ここで、入力文についてロゴヴィスタ翻訳エンジンがいろいろ行なっている評価計算のスケールを表わす数値を紹介します。(13)の数値は、各文について、現在の翻訳エンジンがランク付けの対象としている意味木(図6、図7の意味木参照)の総数です。
(13a)の終止符を含めて3単語の文に316もの意味木が許されるのは、先に述べたように“time”に細分化構文法的特徴を異にする9項目の名詞登録があること、“time
flies”に「時ハエ」、「時間ハエ」、「時飛行」、「時間飛行」など名詞句文としての構文木も、構文法上可能な構文木として、意味解析の対象となるからです。(13b)の8単語文に4416も意味木が許される一つの理由は、"that"が接続詞ではなく指示形容詞の解析、すなわち、「ジョンはあのメアリーが昨日病気であったと言った。」という意味解析も可能であるからです。(13c)は、句読点も含めて37単語の普通の長さの文ですが、この文に可能な意味木の総数は、約48,530,200,000,000,000という天文学的な数です。もちろん種々のヒューリスティックを用いて、ランク付けが高くなる可能性の低い構文木、意味木はどんどん考慮からはずしていきますから、実際に処理しているのは、この意味木セットのごく一部に過ぎませんが、翻訳エンジンが膨大な数の構文木、意味木の処理をしていることには間違いありません。ですから、この文も含めて、入力文のかなり多くのものに、
正しい、あるいはほぼ正しい翻訳がトップ翻訳として出てくることは、驚異的と言わざるを得ません。 また、ロゴヴイスタエンジンを使つての翻訳の過程で、文によっては、翻訳が出てくるのに長い時聞がかかることがあり、どうしてこんな文にこんなに長い時聞がかかるのか、とユーザをいらだたせることがあることと思いますが、ロゴヴイスタの翻訳エンジンは、上に説明したように、正しい翻訳をトップに出すために膨大な計算をしているのです。機械翻訳の精度は、コストなしではあげることができません。それでもなお、自然言語の複雑さをすべて規則化することができず、間違った分析がトップに出てくることがよくあるわけですが、これは文法規則、辞書項目情報の絶え間ない級密化、構文木、意味木の評価テストの絶え間ない改善努力などの積み重ねに頼る以外、解決策がありません。このような努力は、入力文の解析スピードをますます落とす結果をもたらしますが、一方で、コンピュータの計算処理スピードはそれを補って余りある速度で進歩していますので、翻訳スピードも大切ですが、より綴密な解析を行い、できるだけ良い翻訳結果を得ることが重要であると考えています。
 |
5.構文変換
機械翻訳の第5のステップは、構文変換です。構文変換は、格付けの高い意味木から少数に限って(現在の設定では、20個)、その一つ一つに適用されます。構文変換は3段階で行われます。

例えば、規則(4g)には、ターゲット言語が日本語の場合、単純他動調と名詞句の語順を逆にせよという指
定がしてあります。

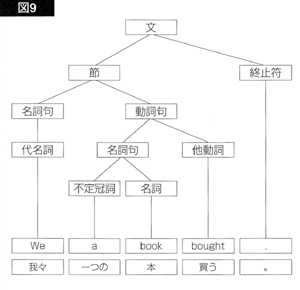
この指定に従って、 図1の構造木は、図9の構造木に変換されます。
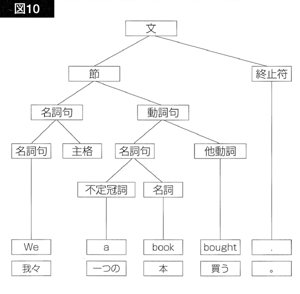
また、規則(4b)には、主語名詞句の後ろに「主格」というカテゴリーを附加し、(名詞句+主格)全体を名詞句とするよう指示されています。

#で始まるカテゴリーは、先に述べた助動詞痕跡 <t>や、名詞句痕跡<e>と同じく、構文解析には用いられないが、構文木作成の段階で挿入されるカテゴリーです。「#名詞句(2)」というのは、「名詞句」というカテゴリーを挿入して、それを、「名詞句+主格」という2つのカテゴリーの親枝点とせよ、という司令です。この司令に基づいて、図9の構造木がさらに図10の構造木に変換されます。
「主格」は、あとで、「は」か「が」という助詞になるべきカテゴリです。

英語では、他動詞の直接目的語、間接目的語は、 前置詞なしの名詞句です。他方、日本語では、これらの名詞句が助詞でマークされなければなりません。この助詞挿入は、動詞の辞書項目の中で指定されます。たとえば、他動詞“meet”の辞書項目には、次のような情報が指定されています。


訳語「会う」の前にある(名詞句:+ に:助詞)という指定は、構文木の中で、「“meet”の直前に「名詞句」という枝点を見つけ、その右に「に」を挿入して、それを「助詞」と命名しなさい」という司令です。この助詞挿入が行われる段階では、構造木の中の枝点は、日本語の語順に並べ替えられているので、“meet”の目的語名詞句は、その直前に見つかるはずです。同様、(16d)の二重自的他動詞“cook”には、辞書の中に次のような情報が指定されています。

上の指定は、意味木の中で「“cook”の直前に(名詞句)(名詞句)という連続する枝点を見つけなさい、そして、その最初の名詞句の右側に「のために」を挿入し、それを「助詞」と命名しなさい。」という司令です。二番目の名詞句に何も助詞挿入の司令がないのは、「を」というデフォルト助詞を挿入すれば事足りるからです。

この段階で、文法規則でも、辞書項目でも指定できない意味木変換が行われます。現在時制、過去時制の動詞の後に、「現在」、「過去」という枝点を挿入するのもこの段階で行われます。また、

という英文で、“wear”の訳語を目的語の意義素に基づいて「かぶる、つける、しめる、する、はめる、 着る、はく」などと訳し分けるのもこの段階で行われる変換です。
この段階で行われる構文変換の一つに

の副詞的不定動詞句を結果節に変換する規則があります。構文解析では、“to find his house burglarized”が目的を表わす副詞句か、結果を表わす副詞句か判定できません。そのため、それは、一応目的を表わす副詞句として分析されます。副詞句は、日本語で動詞句の左に並べ換えられるという一般規則により、第3段階変換が適用される時点では、(21)は、

という語順の意味木になっています。この構造を、英語を日本語の語順で並べれば

に対応する意味木に一大変換するわけです。このためには、“home returned”の後ろに挿入された「過去」という時制指定をコピーして、“(to)
find”の後ろに挿入しなければなりません。そして、“to find his house burglarized”全体をコピーして、再び文末に移動しなければなりません。また、“home
returned”の後ろの「過去」時制は、「家に帰って」を合成することができるよう、「連用て形」という指定に置き換えられなければなりません。ロゴヴィスタの翻訳エンジンの構文変換部門は、これらの指定が一つの規則でできるようにデザインされています。ただし、この規則がどのような条件で適用されるべきかの指定は複雑で、現在のところ、“go
home, “return (home)”など、特定の主文動詞句を含み、不定動詞句は、“find”の動詞品詞のうち特定のものを含んだ意味木に限り、この変換を行っています。
6.形態素生成

機械翻訳の最後のステージは、日本語の動詞、助動詞、形容詞の形態素生成です。今まで、辞書の中で、英語の動詞に与えられている日本語訳は、「買う、会う、飛ぶ」などのように、現在形(すなわち一般辞書登録形)であるように述べてきましたが、ロゴヴィスタの辞書では、実際には、「買w-、会w-、飛b-」などのように、ローマ字子音で終わる語幹のカタチで登録されています。もちろん、「開ける、着る」などは、「開け-、着-」という語幹で登録してあります。
前者のカテゴリーは語幹が子音で終わっているので 子音語幹動詞と呼び、後者のカテゴリーは、ake-,ki-のように語幹が母音“-e,-i”で終わっているので母音語幹動詞と呼びます。このように登録しておくと、形態素生成が非常に規則的、かつ効率的にできます。たとえば、動詞現在形は、子音語幹動詞には-uを、母音語幹動詞には-ruを附加すれば生成できます。

最終の翻訳を出力するとき、ハイフンを取り除いてローマ字の部分をひらがなに置き換えればいいわけです。“wu”は「う」になります。動詞の連用形、命令形、否定形なども、規則的に、生成できます。
(27a,b)の規則に“[形容詞]”が付いているのは、否定形“-ana-,-na”が動詞語幹に附加された後の複合形は、「形容詞」扱いしなさいという司令です。従って、その後に「現在」という時制指定があれば、形容詞の現在形語尾“-i”が附加されます。

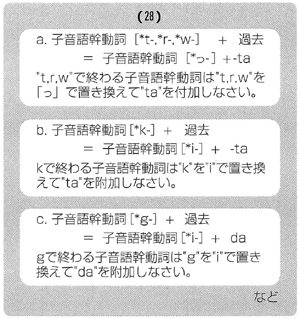
母音語幹動詞の過去形は、“ta”を附加すれば生成できますが、子音語幹動詞の過去形は、完全に規則的ではないので(28)に例示するような、やや複雑な規則が必要です。
(28)のような合成規則で、動詞、形容詞の変化形が合成されると、いよいよ日本文出力の準備完成です。あとは、ローマ字表記になっている語尾の部分をハイフンを取り除きながら、ひらがなに置き換えていけば、漢字仮名まじりの日本文ができます。
ここで特筆しておきたいことは、形態素生成、構文変換の規則がすべてデータファイルとしてプログラムの外にあり、既存の規則を修正したり、新しい規則を追加したりする作業が、エンジニアの手を煩わせずできるということ、またそうしてできた新しい変換規則のセットは、瞬時にコンパイルしてテストできるということです。
これは、翻訳ソフトのユーザにはあまり関係ないことですが、翻訳ソフト開発者にとって翻訳精度の能率的改善のための必須の条件です。ロゴヴィスタ翻訳ソフトの開発者用バージョンは、形態素生成、変換規則だけでなく、翻訳プロセスの過程で参照されるデータを可能な限り、データファイルとして、
プログラムの外に出しています。構文変換の最初の段階として、文法規則で指定されている変換(例えば語順変換)があることを記しましたが、新しい語順変換のパターンが必要になれば、プログラムとは独立したデータファイルで、そのパターンを定義し、文法規則に、そのパターン名を附加するだけで、目的が達成されます。先に、名詞品詞一つ一つに、40余りの構文法的特徴が登録しである、と述べましたが、その特徴の系列のどのポジションがどういう特徴を表わしているか、などの定義もプログラムから独立したデータファイルで指定されていて、エンジニアを煩わせることなく、自由に修正、追加ができるようになっています。また先に、文法規則蓋然性指数、辞書項目品詞蓋然性指数など構文木、意味木のランク付けをする指数のどれにどういう比重を置くかが、指定できるようになっている、と述べましたが、この指定もプログラムの外のデータファイルで行えるようになっています。もちろん文法規則はデータファイルになっています。意義素木もデータファイルで定義されていて、新しい意義素を加えることも自由ですし、また、既存の意義素間の関係を変えることも自由です。また、たとえば動詞が主語に要求する意義素と主語に附加されている意義素との間の接点の有無によって、異なったボーナス、罰金が加えられると述べましたが、このボーナス、罰金の計算の方法も、種々のパラメータの値をデータファイルで指定することによって変えることができるようにデザインされています。
また、機械翻訳で辞書に未登録の単語が入力文に現れたとき、それをどう処理するかが重要な問題になりますが、その単語の語尾がどういうカタチを持っているか、最初の文字が大文字になっているか、数字が入っている単語かなどで、異なった品詞、異なった品詞蓋然性指定、異なった細分化構文法特徴指定、異なった意義素指定などが必要になります。
これらの指定もすべて、データファイルでできるようになっていて、好ましくない翻訳結果がでてきた場合これらの指定をファインチューニングすることが容易ですし、また新しい種類の未知語を設けようと思えば、このデータファイルに追加をするだけで、
その目的が達成できます。
そして、これらのデータファイルの修正結果がミリセカンド単位で新しくコンパイルされた翻訳エンジンに取り込まれ、修正が翻訳の精度に及ぼす結果を瞬時に確認できるようになっています。すでに述べたように、これは、翻訳ソフトのユーザには、余り直接的な関係がないことですが、ユーザから指摘を受けた翻訳の誤りについての対応というようなところで、また、将来に向けての翻訳精度改良のスピード、という点で、重要な要因になってくるものと考えられます。





